




KubeCon�ȵ㱨�棺AIStation����ƽ̨ʵ��RoCE�����´�ģ�͵ĸ�Ч�ȶ�ѵ��
2023/10/16 16:05:40 ��Դ���й���ҵ������
���ԣ����գ���KubeCon + CloudNativeCon + Open Source Summit China 2023��ᣨ���"��Դ�������"���ϣ��˳���Ϣ������"����Kubernetes+RoCEv2�������ģAI������ʩ���ģ��ѵ��ʵ��"���ⱨ�棬�������˳���Ϣ�ڴ�ģ�Ϳ��������У������ڴ��ģRoCE�����ʹ�ó��������ͨ��AIStation�˹�������������ƽ̨�����ģ��ѵ�����ȶ��Ժ�Ч��Ҫ��ʵ�ָ�Ч��ʱ�����ѵ����
�������գ���KubeCon + CloudNativeCon + Open Source Summit China 2023��ᣨ���"��Դ�������"���ϣ��˳���Ϣ������"����Kubernetes+RoCEv2�������ģAI������ʩ���ģ��ѵ��ʵ��"���ⱨ�棬�������˳���Ϣ�ڴ�ģ�Ϳ��������У������ڴ��ģRoCE�����ʹ�ó��������ͨ��AIStation�˹�������������ƽ̨�����ģ��ѵ�����ȶ��Ժ�Ч��Ҫ��ʵ�ָ�Ч��ʱ�����ѵ����
����KubeCon + CloudNativeCon + Open Source Summit��Linux����ᡢ��ԭ���������ᣨCNCF������Ŀ�Դ����ԭ��������콢ʢ�ᣬ��ҵ�����м��ߵ����������Թȸ衢����ѷ��Ӣ�ض���Hugging Face��֪����ҵ�Ľ���λȫ����ר�Ҽ���ҵ������۱����ᣬ������ǰ�ص���ԭ����ؼ����ɹ��ͼ������졣
������ģ��ѵ����RoCE�������ܵ͡��ϵ�����
������ģ���ǵ�ǰͨ���˹����ܲ�ҵ��չ���µĺ��ļ���������ģ��ѵ�����̷dz����ӣ����������ս��
����һ���棬��ģ��ѵ����ͨ�ŵ�Ҫ��dz��ߡ�Ϊ�˻�����ŵ�ѵ��Ч������̨GPU����������ض���InfiniBand��ROCE�ȸ�����������Ϊ�ڵ��ͨ���ṩ�����¡���ʱ�ӵķ�����ͬ�����緽���������ӣ�InfiniBand�����������ѱ�����Ϊ��ģ��ѵ������ѡ������ɱ��ϸߣ�RoCE��Ȼ�ɱ��ϵͣ����ڴ��ģ�����绷���£������ܺ��ȶ��Բ���InfiniBand���������Ҫ�������ģ��ѵ����ͨ�ŵ�Ҫ��Ҫ�Լ�Ⱥ�����е�ͨ���豸����ʹ�ú������������̽������ơ�
������һ���棬��ģ��ѵ������ͨ���������£���Ⱥ����Ч���͡�����Ƶ���Ҵ������ӣ��ᵼ��ѵ���жϺ��ܼ�ʱ�ָ����Ӷ����ʹ�ģ��ѵ���ijɹ��ʣ�Ҳ��ʹ��ѵ���ɱ��Ӹ߲��¡�Meta��ѵ��Open Pre-trained Transformer (OPT)-175B��ģ��ʱ��������һ���������ѵ�����ȶ���Metaѵ����־��ʾ������������Ӳ����������ʩ��ʵ���ȶ�����������������40��Ρ�
����AIStationʵ��RoCE�����´�ģ��Ч�ȶ�ѵ��
������Դ�ģ���з���Ӧ�ø����ڵ������ս���˳���Ϣ�����˴�ģ����������ջOGAI��Open GenAI Infra������"Ԫ������"��Ϊ��ģ��ҵ���ṩ��ȫջȫ���̵���������ջ��OGAI����ջ��5��ܹ���ɣ�����L2��AIStation��Դ�ģ��ѵ���г�����"RoCE�������ܺ��ȶ��Ե�"��"ѵ���ж�"���⣬�ṩ�����ܺͼ����Ծ�ѵ����緽���Ͷϵ���ѵ������Ϊ��ģ��ѵ�����ݻ�����
����1. �Ż�RoCE�����µĴ�ģ��ѵ���������������ܺ��ȶ���
����AIStation�ܹ��ƶ���������ҵִ�мƻ���������ȵ�������Դ������ѵ�������ʱ�Ӻ���������AIStation�Ż�����ϵͳ���ܣ�ʵ������ǧPOD���������ͻ�������������AIStation�Դ��ģRoCE���������µĴ�ģ��ѵ��Ҳ������Ӧ�Ż���ʵ�����������ȶ��Դﵽ��ҵ��ϸ�ˮƽ��
����AIStationͨ��PFC+ECN����������̫���磬�ڽ���������Ʒ��棬PFC��������·����ڱ���-�������ȼ����ڽ�������ڲ����ӵ�����ƣ�ECN�������������ݰ�ͷ�еı�ʶλ���ڽ��������ڲ����ӵ�����ơ����������������ΪKubernetes��Pod������Linux��OFED��������ӵ�����ơ��÷�����Դʹ�����Ҿ������ִε�GPU��������գ������GPU�ֲ�����Ƭ�����⡣
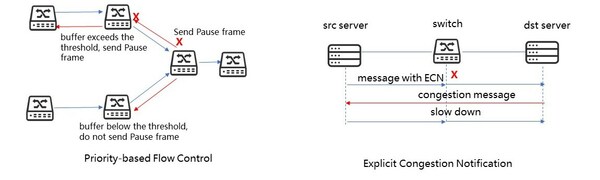
��������PFC+ECN����������̫����
�����ڴ�ģ��ѵ��������AIStationͨ��Calico����Ԫ���ݽ������磬��������RoCE��������RDMAͨѶ���磬��ͨ��CNI�����⻯���ʵ��IP���䣬ʹPOD�ڴ�ģ��ѵ�������ܹ��������NCCL��PXN��ͨ���Ż����ԣ�ʵ������ĸ�Чʹ�á�
��������AIStationƽ̨��ij������ҵ���������������ģ��ѵ����ܣ���DeepSpeed��Megatron-LM�ʹ�����ģ����RoCE���绷���µ�ѵ��������ʵ�ִ�ģ�͵����ʵ����
����2. ���ü��ϵͳ��������άģ�飬���ϴ�ģ���ȶ�ѵ��
������׳�����ȶ����Ǹ�Ч��ɴ�ģ��ѵ���ı�Ҫ����������AIStation���õļ��ȫ��ļ��ϵͳ��������άģ�飬���Կ��ٶ�λоƬ��������ͨѶ�豸�쳣����ϡ�ͬʱ��ѵ�����������ͣ���֣��ٴ��ȱ������н����Զ������滻�쳣�ڵ㣬������ý����ڵ���п���checkpoint��ȡ��ʵ�ִ�ģ�Ͷϵ��Զ���ѵ��
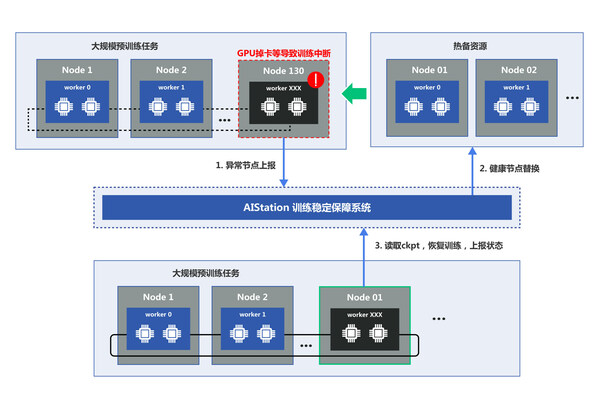
�������ģԤѵ��������쳣�����Ͷϵ���ѵ����
����3. �Զ����û��������ٹ�����ģ��ѵ������
����AIStationʵ���˼��㡢�洢�������ѵ���������Զ������ã�ͬʱ�����û��Զ�������ij�������ֻ�����������������ģ�ͷֲ�ʽѵ�������ң�AIStation�������������Ĵ�ģ��ѵ����ܣ�����Megatron-LM��DeepSpeed��HunggingFace�ϵ���Դ���������ʵ�����뼶�������л������ܹ������������ڴ��ģ��Ⱥ�����±�ݵ��ύ�ֲ�ʽ������ϵͳ���ݷֲ�ʽ�����GPU����������ͨ���������Ե��Ȳ��ԣ�������ֲ�ʽѵ������ļ����ż���
����AIStationƽ̨��AI������Ӧ�ò���ʹ�ģ����ʵ���ϻ����˱���ľ���ͼ��������������ҵ�ͻ�����Դ���������������ʵ�ֽ�����Ч���ڴ�ֱ��ҵ����AIStationƽ̨����ͷ�����ڿͻ���������ҩ����˾���������ܼ�����ѵ������֤��ģ�ͣ���ʹ�ģ��ҵ��ɱ���ij������ҵ���л���AIStation����IJ������㼯Ⱥ��ƾ�����ȵĴ��ģ�ֲ�ʽѵ��֧���������ٻ�2022 IDC"δ�����ֻ����ܹ������"���
�����˳���ϢAIStation�ڴ�ģ�ͷ����Ѿ�ȡ�������ҵ�����ȵľ���ͻ��ۣ�ʵ���˶˵��˵��Ż����Ǹ��ʺϴ�ģ��ʱ����AI��������ƽ̨��δ��AIStation��һ��ͨ���ʹ��롢�����Ĵ�ģ�Ϳ������̣��Լ��ͳɱ���Ч�����������𣬰����ͻ�����ʵ�ִ�ģ�Ϳ�������أ���������ʽAI��չ��
����������
�� ������չʾ����Ϣ����ý��ת�ػ�����ҵ�����ṩ����ԭ�����Լ����г������ֺ�����δ������վ֤ʵ���Ա����Լ�����ȫ�����߲������ݡ����ֵ���ʵ�ԡ������ԡ���ʱ�Ա���վ�����κα�֤���ŵ������߽����ο����������к�ʵ������ݡ�������������ַ����İ�Ȩ���߷���Ȩ����������������Ҫͬ������ϵ�ģ�����30���ڽ��С�
�� �й���Ʒ��Ȩ��������ϵ�й���ҵ��������020-34333079 ���䣺cenn_gd@126.com ���ǽ���24Сʱ����˲�������
 �������ţ����ע
�������ţ����ע��ǩ ��
�������
һ��������Ѷ�������










 ���������� 44010602001889��
���������� 44010602001889��