




"算力猛兽"浪潮NF5468A5 GPU服务器开放试用免费申请
导言:近期,一系列针对浪潮NF5468A5服务器的专业测评不断发布,报告显示这款GPU服务器在典型的AI计算场景拥有超乎预期的卓越性能,在MLPerf Training、MLPerf Inference、Alphafold2、NAMD、HPL、Stream等各种典型应用评测中展示出了让人惊叹的领先性能,因而被媒体称赞为"算力猛兽"。浪潮信息官网显示,NF5468A5正在进行"超值机型 限免试用"活动,对算力有强大需求的用户都可以免费申请。
近期,一系列针对浪潮NF5468A5服务器的专业测评不断发布,报告显示这款GPU服务器在典型的AI计算场景拥有超乎预期的卓越性能,在MLPerf Training、MLPerf Inference、Alphafold2、NAMD、HPL、Stream等各种典型应用评测中展示出了让人惊叹的领先性能,因而被媒体称赞为"算力猛兽"。浪潮信息官网显示,NF5468A5正在进行"超值机型 限免试用"活动,对算力有强大需求的用户都可以免费申请。
NF5468A5是浪潮信息推出的一款面向AI训练、AI推理、HPC、视频处理等多种应用场景的GPU服务器,在4U空间内搭载2颗AMD EPYC处理器,支持多达8张双宽加速卡,巧妙的分区散热设计有效实现CPU与GPU模组的分流,同时通过PCIE 4.0直连有效降低CPU和GPU间的通信延迟。该服务器支持高达8T的DDR4内存、409.6 GB/s的内存总带宽,并且提供了8个全高全长双宽PCIe x16的物理插槽。其强劲的处理器性能、巨大的内存容量和带宽、丰富的IO扩展,特别适合AI计算、云计算、HPC以及企业各类业务的工作负载。
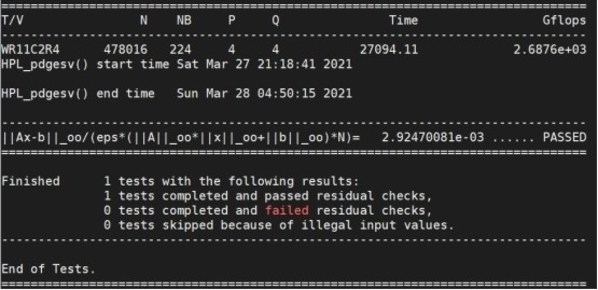
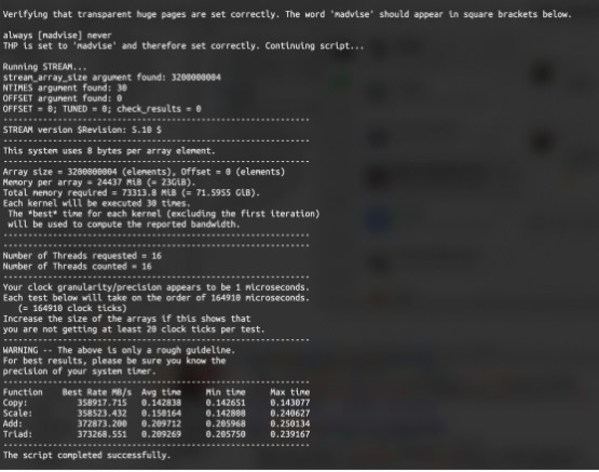
媒体对NF5468A5进行了一系列测评。其中HPL测试结果表明,NF5468A5搭载2颗AMD EPYC 7543处理器,浮点计算速度为2.69 TFLOPS,根据AMD平台理论浮点计算速度,处理器计算效率达到93.74%。在STREAM测试中,由于采用多线程并行,实测结果内存带宽373 GB/s,对比平台内存理论带宽,实测内存带宽效率同样达到惊人的91.1%。
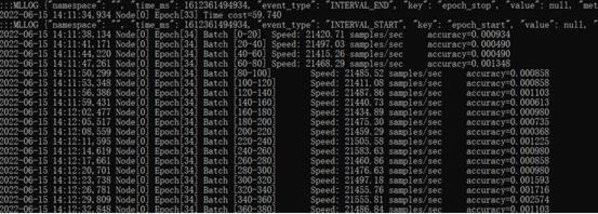
在AI训练性能测试中,浪潮NF5468A5搭配8张NVIDIA A100 PCIE 40GB GPU,使用MLPerf Training V1.0代码训练卷积神经网络ResNet50,每秒处理的图片数量可以达到21486张,单台机器35分钟即可完成Resnet50模型训练。参考最近几期MLPerf训练榜单,搭载8张NVIDIA A100 40G GPU卡的服务器的最好成绩是36.2分钟。可以说,在同等GPU配置的服务器中,浪潮NF5468A5的ResNet50训练性能是最好的。
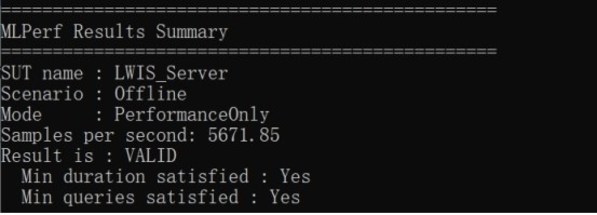
在AI推理性能测试中,搭载1张NVIDIA Tesla T4 GPU的NF5468A5,使用MLPerf Inference V1.0代码,ResNet50测试结果为每秒处理5671.9张图片,这份成绩也是非常出色的。同时,NF5468A5能够很好地支持寒武纪MLU270-S4推理加速卡,Caffe框架下的ResNet18计算性能每秒超过7000张图片。
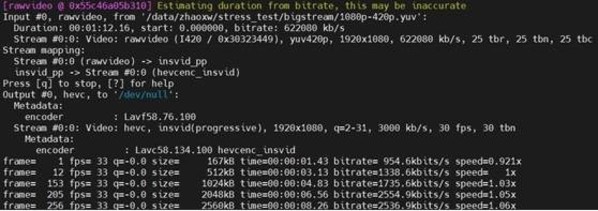
同时,媒体还对浪潮信息自研的专用加速器M10A进行了性能测试,结果表明,浪潮NF5468A5搭配1张M10A,可实现480fps 1080P视频的流畅转码,一张M10A的视频处理能力相当于一台双路服务器的性能。此外,NF5468A5搭载1张RTX3090显卡,ETHASH算法性能突破100MH/s。
浪潮NF5468A5+单卡RTX3090 HASH算法测试结果
|
算法 |
ETHASH |
ETCHASH |
AUTOLYKOS2 |
BLAKE3 |
MTP |
MTP-TCR |
OCTOPUS |
|
性能 |
108MH/s |
108MH/s |
232MH/s |
2.44GH/s |
7.23MH/s |
28.78MH/s |
103.07MH/s |
|
算法 |
KAWPOW |
PROGPOW |
PROGPOW-VEIL |
PROGPOW-VERIBLOCK |
PROGPOWZ |
FIROPOW |
/ |
|
性能 |
55MH/s |
54.4MH/s |
54.85MH/s |
27.31MH/s |
54.37MH/s |
54.91MH/s |
/ |
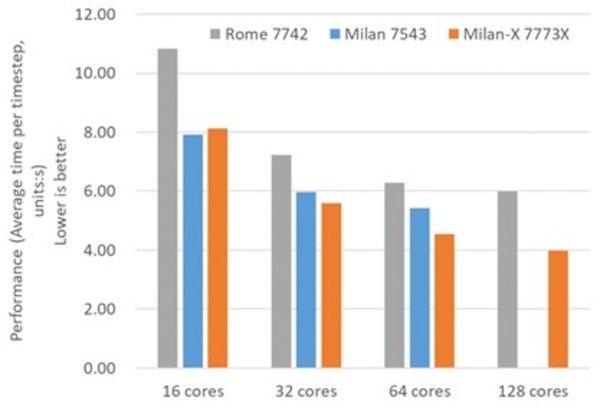
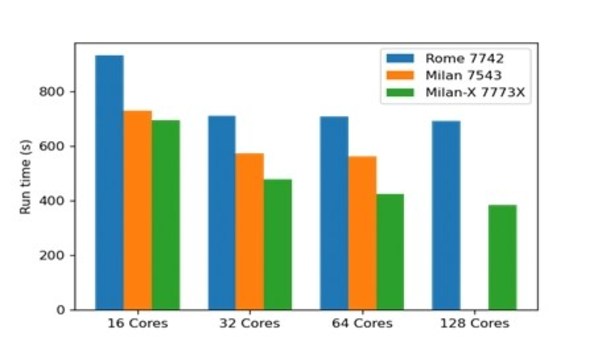
NF5468A5在HPC应用性能方面同样有非常优秀的表现。媒体在NF5468A5平台上搭载了2颗AMD Milan-X 7773X运行常见的气象应用WRF和计算流体力学应用OpenFOAM进行性能基准测试。测试数据显示,WRF测试其性能相比同平台搭载两颗Rome 7742处理器的计算性能提升23%~34%;而在OpenFOAM测试中,其性能相比同平台Rome 7742处理器计算性能提升34%~80%。
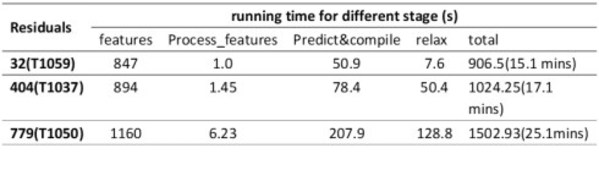
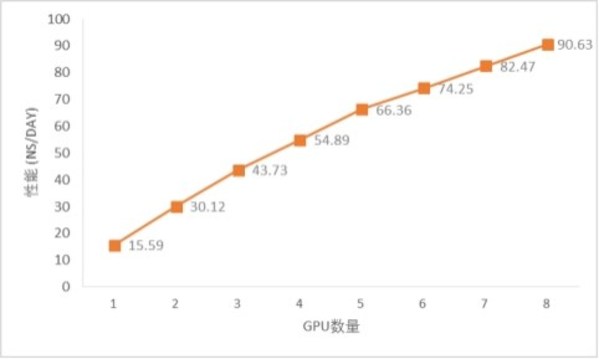
在最新一期评测中,媒体还对NF5468A5服务器在AI+Science应用场景的表现进行了全面的测评。测试选择了两项近期大热的应用AlphaFold2和NAMD。评测结果发现,对于长度在1000以内的蛋白序列,结构预测的完整时间基本在半小时以内,意味着一台NF5468A5服务器一天可以完成至少384个Alphafold2蛋白序列的预测任务;对于分子动力学模拟来说,STMV算例在NF5468A5上可以实现90.6ns/day的计算速度,一台服务器一天就能实现100万原子近100ns的模拟。浪潮NF5468A5 GPU服务器可以满足绝大多数科研团队在AlphaFold2、NAMD等科学应用领域的AI加速计算需求。
NF5468A5+单张A100预测得到的AlphaFold2 top1模型计算性能
通过多次不同配置、不同场景的深度评测,媒体认为浪潮NF5468A5是一款性能强大、应用场景广泛的GPU服务器。该服务器硬件设计合理,可最大化发挥核心组件的性能优势,并通过分区散热设计保障服务器稳定运行。同时,NF5468A5广泛兼容主流加速卡,以更灵活的计算架构最大程度地满足用户在图像识别、自然语言处理、语音识别等多场景应用需求。
目前,据浪潮官网显示NF5468A5正在推出 "超值机型 限免试用"活动,感兴趣的用户不妨申请,一试究竟。
免责声明:
※ 以上所展示的信息来自媒体转载或由企业自行提供,其原创性以及文中陈述文字和内容未经本网站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本网站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。如果以上内容侵犯您的版权或者非授权发布和其它问题需要同本网联系的,请在30日内进行。
※ 有关作品版权事宜请联系中国企业新闻网:020-34333079 邮箱:cenn_gd@126.com 我们将在24小时内审核并处理。
 更多新闻,请关注
更多新闻,请关注标签 :
相关网文
一周新闻资讯点击排行








 粤公网安备 44010602001889号
粤公网安备 44010602001889号