




技能大模式Skill Model重磅发布 浪潮"源"大模型加速AI生产力升级
导言:近日,浪潮信息发布了基于"源1.0"大模型生成的4个技能大模型(Skill Model),分别为对话模型"源晓问"、问答模型"源晓搜"、翻译模型"源晓译"、古文模型"源晓文"。
近日,浪潮信息发布了基于"源1.0"大模型生成的4个技能大模型(Skill Model),分别为对话模型"源晓问"、问答模型"源晓搜"、翻译模型"源晓译"、古文模型"源晓文"。这些技能大模型在各自细分领域的精度业界领先,可直接应用于人机交互、知识检索、语言翻译和文学创作等领域,模型运行速度最高提升9倍。更重要的是,基于大模型快速生成特定领域的技能大模型(Skill Model),也意味着"源"的AI生产力大幅升级,能够帮助商业组织和研究机构实现对AI技术的高效、快速和低成本应用,加速产业AI化。
技能大模型(Skill Model):大模型生产方式的新变革
应用场景的碎片化导致大量的定制化,是当前人工智能从技术向应用转化过程中,遇到的一个突出问题。千行百业使用人工智能,如果一个场景一个场景的去定制,无论是时间成本还是人力成本都很高,维护的难度也很大。大模型的出现,使得模型的生产效率得到了极大的提高,技能模型就是典型的代表。
所谓技能大模型(Skill Model),是指面向特定行业或场景,通过知识蒸馏、模型裁剪、模型压缩等技术,通过通用大模型生成具备该行业或场景所需特定技能的专业模型,在保留通用大模型的知识、认知推理能力及泛化能力基础上,实现针对该领域的技能专业化、模型轻载化和调用标准化。
"技能大模型(Skill Model)"带来了AI模型生产方式的新变革,将原本耗时数月经年的大模型开发训练周期,缩短至短短数周,极大降低了开发与训练成本。技能大模型(Skill Model)的价值在于,其针对特定领域进行了强化学习,能够实现与通用的基础大模型相当或更好的性能表现,且拿来即用,使用门槛更低,应用效果更佳。同时由于模型的轻载化特点,使其便于部署且消耗计算资源更少,能够显著减低使用成本和维护难度。
此外,技能大模型(Skill Model)还可以与通用大模型协同进化,它的执行结果反馈给通用大模型后,能够让通用大模型的知识与能力持续进化,即落地场景越多、模型进化得"越聪明",同时模型进化的速度也越快。
浪潮信息副总裁刘军表示:"研发大模型需要千万元的训练成本,海量数据集及巨大的算力资源,这对很多客户来说是个巨大的门槛,我们希望通过"技能大模型(Skill Model)"的模型生产方式变革,推动AI生产力的升级,让行业用户甚至是中小用户也能利用大模型开展深度创新,从而加速整个社会的智能化升级。"
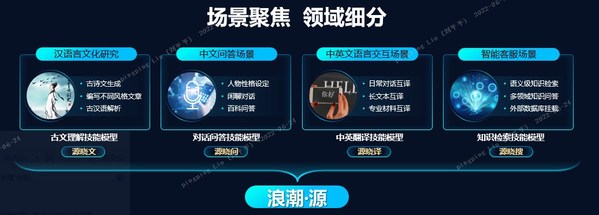
四大技能模型重磅发布: 对话、问答、翻译、古文
此次浪潮信息发布的四大技能模型(Skill Model),在继承"源1.0"大模型通用的知识与能力基础上,面向特定领域的场景进行针对性的技能优化,模型精度和训练效率均处于业界领先:在十分之一参数量的情况下,即可在相同任务上复现98%的通用大模型效果,推理速度最高提升9倍。
对话模型("源晓问")在源大模型基础上,又采用了2660万条医疗、法律、保险等不同行业,历史、电影、娱乐等不同场景的对话语料数据进行强化训练,在高频闲聊、知识问答等开放式问答对话上表现突出,打榜业界权威测评WebQA开放问答数据集及CUGE两项榜单均位居榜首。作为高水平对话问答技能模型,源晓问可广泛应用于虚拟人、智能助手、智能客服等场景。目前已经有开发者在GitHub社区发布了由源1.0进行角色扮演的剧本杀实录,源1.0的场景化对话技能已经达到了"人机难辨"的程度。
翻译模型("源晓译")基于源大模型阅读的海量高质量数据集,采用维基百科、书籍、联合国文件及字幕组等近80G高质量数据集进行强化训练,因此翻译不但流畅准确,同时更符合中文表述,在中译英时表述更加专业地道,可轻松应对日常对话、新闻、哲学、小说等日常的语言翻译任务。翻译模型打榜业内权威WMT数据集及CUGE两项榜单均位居榜首。
问答模型("源晓搜")链接了包含了维基百科、书籍等知识的数据库,根据用户提问的内容,利用高性能检索方法,快速地从知识数据库中检索到与提问内容相关的内容作为背景知识,在相关专业知识背景下回答问题,能够生成符合人类语言习惯的专业答复。问答模型支持不同领域知识检索,仅通过替换链接的知识库便可实现在不同专业领域之间的适配,实现了搜索和生成的一体化框架,能满足不同领域知识检索的需求,可广泛应用于医疗、法律、保险及娱乐等领域的智能客服、个人助理等场景。此前在打榜WebQA任务上,问答模型以55.97%的准确度在业界遥遥领先。
古文模型("源晓文")在源大模型精读了5000GB高质量中文的基础上,又学习了先秦到近代几乎所有诗词,并精选其中最优秀的10万首进行强化训练。海量学习兼针对性强化训练使得古文理解模型能够精通古诗词的用词、文法及平仄格律等规则,还擅长营造意境、引经据典,同时兼具古文解析的能力,因此古文模型能够轻松解决今年高考古文翻译、诗词鉴赏等题目,在"金陵诗会"活动中,短短3天作诗近2000首,可广泛应用于文学创作、古诗文教学、汉语言文化研究等场景中。
"源1.0"是浪潮信息在2021年发布的巨量中文语言模型,参数量高达2457亿,比此前OpenAI发布的GPT-3大模型,参数量增加40%,训练数据集提升10倍,发布时便问鼎中文语言理解评测基准CLUE榜单的零样本和小样本学习两类总榜冠军。目前,"源1.0"已经相继完成了模型API、高质量数据集、模型训练代码、推理代码和应用代码等等内容的开源开放,在GitHub社区、浪潮源官网均可以申请获取相关的资源,已有超600家用户借助"源1.0"提供的数据集和API,构建了覆盖金融、互联网、医疗和自动驾驶等行业的高水平人工智能应用。
免责声明:
※ 以上所展示的信息来自媒体转载或由企业自行提供,其原创性以及文中陈述文字和内容未经本网站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本网站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。如果以上内容侵犯您的版权或者非授权发布和其它问题需要同本网联系的,请在30日内进行。
※ 有关作品版权事宜请联系中国企业新闻网:020-34333079 邮箱:cenn_gd@126.com 我们将在24小时内审核并处理。
 更多新闻,请关注
更多新闻,请关注标签 :
相关网文
一周新闻资讯点击排行












 粤公网安备 44010602001889号
粤公网安备 44010602001889号