




Kneron������һ���ն��˹����ܴ�����NPU IP-KDP Series
2018/9/14 15:15:00 ��Դ���й���ҵ������
���ԣ�9��14�գ�רע���ն��˹����ܽ���������´���˾���� (Kneron) �������Ϻ����е� Arm �˹����ܿ�����ȫ���ᣬ�ԡ����ع��㷨��AIоƬ�е�Ӧ�á�Ϊ���ⷢ����˵������ͬʱ���� Kneron ��һ���ն��˹����ܴ�����ϵ�� NPU IP - KDP Series
����Ч�ܴ������3������߿ɴ�5.8 TOPS
9��14�գ�רע���ն��˹����ܽ���������´���˾���� (Kneron) �������Ϻ����е� Arm �˹����ܿ�����ȫ���ᣬ�������ع��㷨��AIоƬ�е�Ӧ����Ϊ���ⷢ����˵������ͬʱ���� Kneron ��һ���ն��˹����ܴ�����ϵ�� NPU IP - KDP Series��Kneron �ڶ��� NPU IP ���������Ʒ���ֱ�Ϊ�����İ� KDP 320������ KDP 520���Լ���Ч�ܰ� KDP 720��ȫϵ�в�Ʒ�Ĺ��ĵ���0.5��(W)�������µļܹ������������ߵ��ԣ�����Ч���������һ����Ʒ���������3������������ (peak throughput) ��߿ɴ�5.8 TOPS��ÿ�����ڴ����㣩���]һ����
Kneron ��ʼ�˼� CEO �����ϱ�ʾ����Kneron �Ƴ�Ϊ�ն�װ������Ƶ��˹����ܴ����� NPU IP ���䳬���ĵ������ܵ��г��߶ȹ�ע��Kneron ��һ�� NPU ��Ʒ������ȡ��������ͻ�ƣ����ڵ�һ����Ʒ�����ƣ����Ǹ��������������̡�������������Ч���봢����Դʹ���ʣ�ͬʱ��Բ�ͬ��������ģ�ͽ����Ż����� NPU ���Ը��㷺��Ӧ���ڸ����ն�װ�ã�����������ӵ�����������
Kneron NPU IP ��Ӧ���������ֻ������ܼҾӡ����ܰ������Լ������������豸�ϣ����ն�װ�����������¾������и��������硣Kneron �ڶ��� NPU IP �����µĽ���ʽ����ܹ� (Interleaving computation architecture) ��ƣ������������̺�����Ч�ʡ����ѹ�� (Deep compression) ������ѹ�����ܴ�ģ�Ͳ㼶���������ݺͲ����㼶��ʹѹ��������������̬������Դ���书������������Դ�����ʣ�ȴ��Ӱ������Ч�ܡ����⣬֧�ָ��㷺�ľ��������� (Convolutional Neural Networks, CNN) ģ�ͣ�����Ը��� CNN ģ�ͷֱ�����Ż����ڲ�ͬ������ģ���£�������Լ1.5����3�����ȵ�Ч�ܡ�
�ڶ��� NPU IP-KDP Series �ص㼼��˵����
����ʽ����ܹ���ƣ�������ʽ�ܹ�����������ܹ�����Ҫ�ľ��� (convolution) ��ػ� (pooling) �����ƽ�н��У���������������Ч�ʡ����µľ������У�����ͬʱ֧�� 8bits �� 16bits �Ķ������� (fixed point)����������е��ԡ�
���ѹ��������������ִ��ģ��ѹ�������ܶ������е����ݺͲ��� (coefficient) ����ѹ���������ڴ�ʹ�á�ģ�ʹ�С��ѹ����50��֮һ���£�ȷ�ȵ�Ӱ����С��1%��
��̬������Դ���䣺�ù����ڴ� (shared memory) �������ڴ� (operating memory) ֮����Խ��и���Ч����Դ���䣬����������Դ�����ʵ�ͬʱȴ��Ӱ������Ч�ܡ�
CNNģ��֧���Ż���֧�ָ��㷺�� CNN ģ�ͣ����� Vgg16��Resnet��GoogleNet��YOLO��Tiny YOLO��Lenet��MobileNet��Densenet �ȣ�������Բ�ͬ CNN ģ�ͷֱ�����Ż����ڲ�ͬ������ģ���£����^��һ���aƷ����Լ1.5����3��Ч�ܡ�
עһ������Ч�ܻ��������Ƴ̲�ͬ���졣5.8 TOPS Ϊ KDP720 �� 28 �����Ƴ̡�600 MHz��8bit fixed points �µ�Ч�ܱ��֣�Ԥ�����й����� 300-500mW������ÿ��Ч��Ϊ13.17 TOPS/W�� ��

����������
�� ������չʾ����Ϣ����ý��ת�ػ�����ҵ�����ṩ����ԭ�����Լ����г������ֺ�����δ������վ֤ʵ���Ա����Լ�����ȫ�����߲������ݡ����ֵ���ʵ�ԡ������ԡ���ʱ�Ա���վ�����κα�֤���ŵ������߽����ο����������к�ʵ������ݡ�������������ַ����İ�Ȩ���߷���Ȩ����������������Ҫͬ������ϵ�ģ�����30���ڽ��С�
�� �й���Ʒ��Ȩ��������ϵ�й���ҵ��������020-34333079 ���䣺cenn_gd@126.com ���ǽ���24Сʱ����˲�������
 �������ţ����ע
�������ţ����ע��ǩ ��
�������
һ��������Ѷ�������






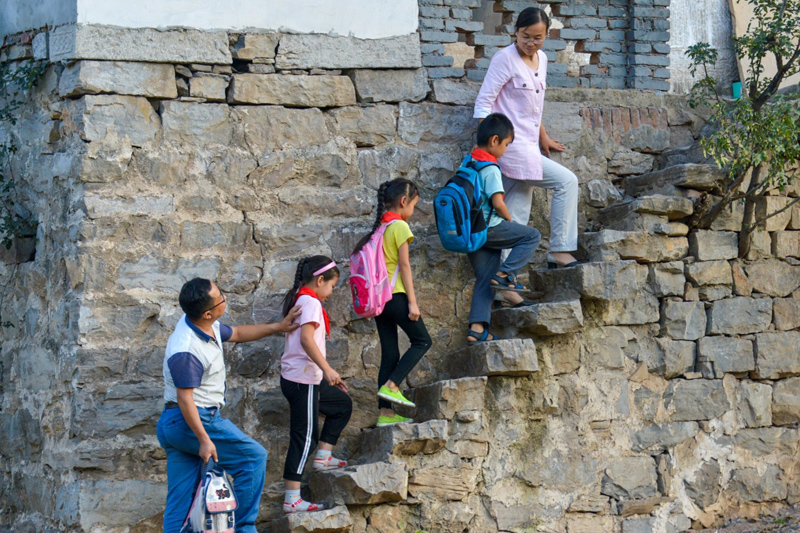





 ���������� 44010602001889��
���������� 44010602001889��